for more information, contact Kenneth A. LaBel
![]()
Paul Marshall, Consultant
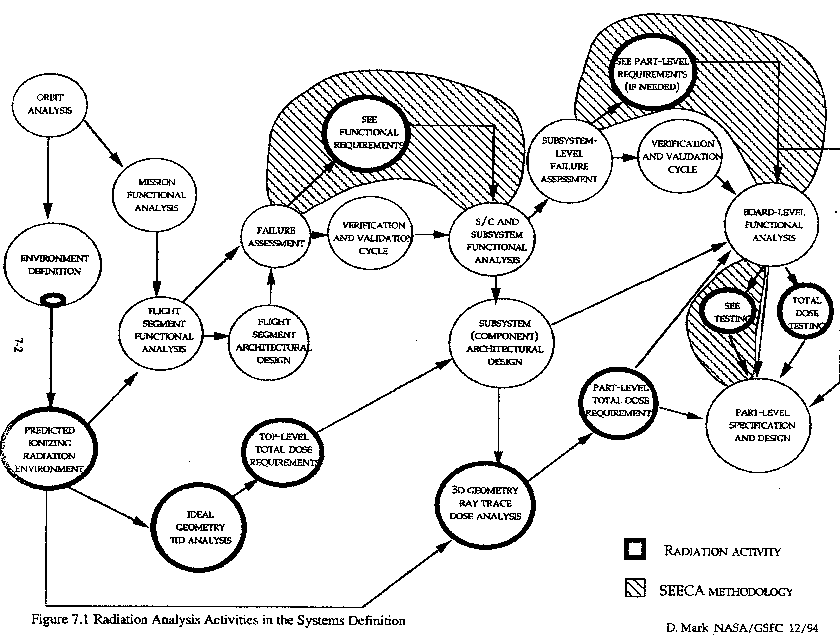
In this section we describe how SEECA applies to system level requirements generation and flowdown. Figure 7.1 depicts the flow of the criticality analysis as it occurs with other stages of radiation evaluation activities in the generalized system design process. From this figure, we see the bold outlined boxes which address specific stages of the process pertaining to radiation effects and analysis. Recognizing the time and design stage progression from right to left in the figure, these tasks can be broken out of the overall effort as follows:
[1] Ionizing radiation environment prediction
[2] Ideal geometry total ionizing dose analysis
[3] Top-level total ionizing dose requirements definition
[4] Top level SEE functional requirements
[5] 3-D geometry ray trace dose analysis
[6] Part level total dose requirements
[7] Part level SEE requirements
[8] SEE testing and design verification
[9] Total ionizing dose testing and design verification
As the figure depicts, the SEECA methodology involves steps 4,7, and 8. Also, it ties in with system and subsystem failure assessment and system/board level functional analyses as is indicated.
In the remainder of this section, we track these processes and indicate the roles of the various specialists (system engineers, project managers, design engineers, and radiation effects engineers) through the timeline as it progresses from mission definition to system design verification.
Mission planners ultimately decide the radiation environment in which the satellite will need to function, and this is usually done in a manner which maximizes performance while minimizing radiation exposure. Even so, most missions will at some point encounter considerable particle exposures whether in the South Atlantic Anomaly or from energetic solar particles ejected from solar flares. Also, as discussed in Section 3, the heavily ionizing cosmic ray environment extends to all orbits to some degree. The anticipated particle environment then follows from the orbit and the mission time with respect to solar activity, and the models for predicting these environments have been described in section 3.
As part of the requirements, there should be unambiguous statement of the environment in which the system will need to operate as it pertains to SEE. For this purpose, the total ionizing dose environment or depth dose curves alone are not adequate, in addition the requirements specifications document should include detailed information of the various SEE environments. For example, the cosmic ray environment should be specified as an LET spectrum with identification of the models and the conditions used in calculating the spectrum. Likewise, proton environments should be specified according to the worst case fluxes and energy. If the requirements cover solar flare conditions separately from "normal" environmental conditions, there should be spectral and flux information provided here as well. Typically, these environmental descriptions will assume some nominal shield thickness (e.g. 80 mils Al), and provisions should be made for modifications to the specified environment to allow calculation of SEE rates for more heavily shielded parts.
The system level requirements for SEE performance should be viewed as largely independent of the orbital particle environment. Even so, when establishing system requirements, it is essential that they be expressed with the needs for satisfactory performance in the presence of ionizing particles. These requirements should be expressed in view of all the possible ways in which single event effects could compromise mission performance. The two main categories are system availability and information quality.
System Availability
System availability requirements address extreme events leading to possible loss of mission as well as less severe events which might require ground station or possibly autonomous reset with a brief disruption in system performance. It is the decision of mission planners to determine what level of temporary outage is acceptable (and affordable), along with establishing appropriate ways to restore operability.
Typically, availability requirements for single event effects have been expressed in general terms along the lines of "no single event effect (e.g. latchup or any other potentially catastrophic SEE related failure mode) shall be allowed to result in the loss of the mission." In terms of requirements, this represents the SEE equivalent to the conventional reliability requirement of not allowing single point failures to result in mission loss, though the analysis for assessing risk and the details of meeting the requirement will certainly differ between the SEE and hard failure cases. System availability is also an appropriate way of expressing requirements for specific mission functions, which might flow directly into a subsystem level availability requirement.
Additional availability requirements can be specified in terms of the severity of disruption, the acceptable frequency of disruption, or the maximum duration of disruption, or some combination of the three. In addition to SEE induced hard failures, soft errors may occur which disrupt system performance but allow complete system recovery. For example, it might be required that normal mission functions not be disrupted by any single event effect with an outage requiring ground station intervention more than once per year, and the occurrences of autonomously reset disruptions cannot happen more than once daily with the system recovery required to result in an overall system availability of 0.9993 (corresponding to system unavailable for 1 minute per day on average).
SEE requirements might also reflect the compromise between mission objectives and cost constraints by allowing for less stringent performance under extreme circumstances. For example, if the mission science objectives of a LEO platform do not require highest availability levels while in the SAA, then the SEE/SEU requirements might be relaxed in that region with substantial cost savings. Similarly, if more frequent disruption of operations could be tolerated for short durations over the course of a multi-year mission, then requirements could be relaxed for anticipated solar flare related particle bombardment which might be several orders-of-magnitude more harsh than daily peak particle fluxes under normal conditions.
Information Integrity
As a separate requirement from system or subsystem availability, the mission might consider the payload functional requirements in terms of information integrity. In many cases, soft errors can occur in a relatively benign manner which affect data without altering the system functions. For example, a soft error in a sensor A/D converter or in a data path might result in a glitch in an image. Such errors to not interrupt the flow of information, but rather degrade its quality.
These less severe types of single event errors lend themselves to EDAC techniques as described in Section 6. The implementation of EDAC and the type of approach selected should be based on the following: the environment, the hardware, and the requirements for data integrity. The establishment for reasonable requirements at the mission planning stage should lead to acceptable, but not necessarily error free, performance within constraints of cost and design complexity.
The form of the data integrity requirement for the payload will likely reflect the type of information being collected and how it is handled between collection and downlink. As an example, a charged coupled device (CCD) for earth imaging might be the source of a data stream which flows from a camera through a data bus to a solid state recorder and then to a downlink. In such a case, the top level requirement might be for example, no more than 3 bad pixels per frame of imagery. Another form for a top level requirement in this example might be a bit error rate (BER) requirement. The establishment of such top level requirements provide the basis for subsequent SEE criticality subsystem assignments as the error budget is allocated to the various potential sources (e.g. proton events in the CCD's pixels, SEU in the camera ADC, bit errors in the data bus, soft errors in the solid state recorder, etc.). Sections7.3 and 8 will illustrate the details of this process using specific examples.
Just as with the availability requirements already discussed, the top level data integrity requirements could be tailored to the mission needs in terms of different performance levels for different aspects on the environment (e.g. SAA and solar flare protons). Whenever the most demanding performance requirement can be divorced from the most severe environmental conditions, mission complexity and cost can be reduced, and it is the proper expression of the top level system requirements which allow this.
In summary, SEECA serves as the foundation for developing top level SEE requirements through both preliminary and detailed design phases. These requirements are essential to provide reasonably reliable and acceptable mission performance within the constraints of satellite complexity and cost. Top level requirements should assure both the availability of the satellite to perform its designed function, and the integrity of the information provided. Where it makes sense, cost and complexity savings can result from requirements which are multi-tiered, with relaxed performance required during extreme environmental conditions.
The generation of top level SEE requirements should follow from a coordinated effort between mission planners, systems engineers, radiation environment specialists, and radiation effects engineers. Ultimately, compliance with these top level requirements should be demonstrated with test data and analysis. Too often, improper or incomplete SEE requirements are generated, resulting in ambiguous design objectives. If the top level requirements do not provide sufficient guidance with respect to SEE, then the procured system either should not be expected to function adequately or the mission costs will not be minimized.
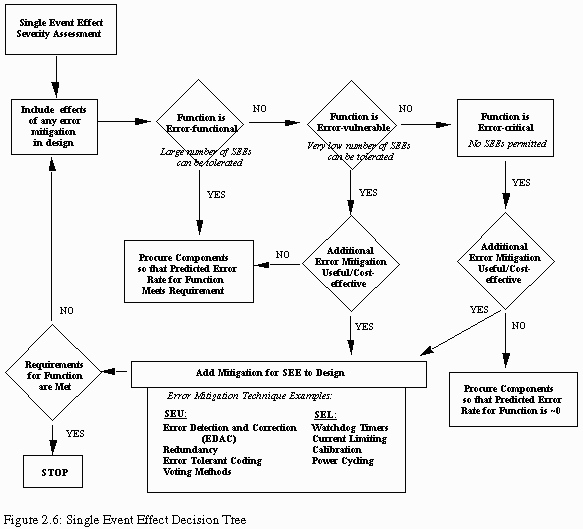
As a part of mission planning, functional requirement definitions for each primary function are established, and this may occur without consideration of radiation effects. As part of the single event effects assessment, these same functions must be ranked according to the degree of severity their temporary disruption or permanent loss would impose. As discussed in Section 2.3, the SEE criticality of a given mission operation is assigned along these functional rather than component or subsystem boundaries. Section 2.4 also has suggested a hierarchical scheme for ranking SEE criticality as error-functional, error-vulnerable, or error-critical corresponding to little or no concern, low rates acceptable, and no events acceptable respectively. The decision tree in figure 2.6 provides a means for determining the severity of a single event based on the criticality ranking of the function which it affects.
Functions can be broadly sorted into payload versus bus groupings. Bus functions would typically include Telemetry and Control, Power and Power Distribution, Data Bus and Mass Memory Storage, Downlinks, etc. whereas payload functions would tend to be more mission specific and include things such as UV / Visible Imaging, Infrared Imaging, Environment Monitors, etc. Obviously, all are important functions, but some (especially those associated with the bus) are clearly mission critical. Even though Telemetry and Control or other essential functions are always protected against any single point failure by dual redundant hardware architectures, it is usually assumed that loss of a redundant portion of a critical subsystem should not be allowed to occur due to a SEE. Thus all subsystems supporting mission critical functions would typically be designed assuming error-critical levels.
Other functions, for example a secondary experiment payload to evaluate a new technology, might be considered of less importance, and the only mission imposed requirement might be that a failure within the experiment, SEE induced or otherwise, must not affect the host. Even so, the experiment designers would likely have considerable investments in the experiment and would consequently impose their own higher level criticality rankings to assure the success of the experiment.
In between these two extremes we have the error-vulnerable category in which a certain number of errors could be tolerated or mitigated with acceptable performance. Many satellite functions are inherently error-critical, but wherever error-critical ratings can be avoided, they should be. The error-vulnerable category allows considerable flexibility in providing acceptable performance with reliance on less expensive parts and less complex systems.
Since SEE is actually a catch-all category comprised of several types of effects (see Section 4), realistically, the analysis tree of figure 2.6 should be evaluated for the consequences of each type of effect. For example, a payload function might be considered error-vulnerable for soft errors, but error-critical for hard errors. This might translate to use of a memory with sensitivity to proton-induced upsets and the use of EDAC to meet performance requirements, but require that it not latch up or exhibit SEE induced stuck bits. Indeed, functions which might be susceptible to hard errors from stuck bits, destructive latchup, or gate rupture would usually lead to more restrictive criticality ratings for those effects than for soft errors.
As the mission development progresses from planning to satellite conceptual design, the satellite functions are divided across various hardware subsystems, each of which will have to perform within certain measures to meet system top level functional requirements. Along with the division of satellite functions across these subsystems, as described in Section 2, the preliminary design phase will also include a set of derived SEE requirements which will flow out of the top level SEE requirements.
As with the case of top level requirements, the subsystem derived requirements should be expressed in terms of availability and, where appropriate, information integrity. It is the role of the team comprised of the radiation environment and effects specialists, the subsystem lead engineers, and the system engineers to establish the subsystem level derived requirements based on the subsystem function, as described in Section 2.3. The budgeting of availability and information integrity requirements may occur across multiple subsystems where those subsystems are functionally related. In no case should the availability or performance of the subsystem (or collection of functionally related subsystems) be designed with SEE vulnerability in excess of that allowed based on the functional criticality.
In terms of the example set forth in Section 7.2, the mission requirement might be for the collection of image data with a CCD camera. Functionally, this requires several subsystems including Telemetry and Control, Pointing and Tracking, Power Distribution, the CCD Camera Payload, the High Speed Data Bus, the Solid State Recorder, and the Downlink. Obviously, a number of these are mission critical, and will carry error-critical criticality ratings for that reason.
However, the transmission of CCD imagery, which might be a primary mission objective, would not necessarily be deemed error-critical, and the costs associated with guaranteeing uninterrupted, error-free data might be prohibitive. In this case, availability and information integrity allowances could be applied to the function of CCD image collection and transmission in the top level requirements. It is then the task of the engineering team to allocate this error allowance between the CCD Camera, Data Bus, and Solid State Recorder subsystems. This is typically done along with functional requirements definition in the preliminary design phase (see Section 2.3), and it necessarily relies on past experience and educated guesswork with anticipation of the trades associated with the degree of difficulty in hardening against or tolerating SEE in one subsystem versus another.
In this manner, functional requirements from the top level and associated SEE criticality levels for those functions are translated into SEE requirements at the system and subsystem hardware levels. This allocation of error allowances necessarily must occur early in the preliminary design, but it may be a dynamic process which continues into the detailed design and through test and evaluation phases. With system cost and complexity always guiding the trades, the reallocation of SEE error allowances may be required due to a number of factors, such as the availability (or cost) of SEE hardened parts or test results on candidate components indicating different sensitivities in ground radiation tests than anticipated based on initial information. In this sense, there exists an advantage to satellite procurement approaches which allow for allocation and modification of error budgets among various subsystem suppliers.
At this point we have established functional SEE requirements with assigned criticality levels, which in turn have been applied to error allocation budgets at the hardware subsystem level. It is now the task of the subsystem engineering team to allocate their error budgets among the various segments of the subsystem in a manner which minimizes the system cost and complexity. Again, this occurs early in the subsystem design and may be modified iteratively as the detailed design progresses for the reasons previously stated. At this level the trade space involves component choice selection and error mitigation approaches, and now the environment details are incorporated to predict SEE rates (See Sections 4 and 5) and evaluate the efficacy of the candidate design approaches.
As part of the evaluation, it is necessary to review candidate approaches to assess the possible SEE related failure modes which may occur. This represents the equivalent to the familiar Failure Modes Analysis from conventional reliability analysis, and for complex logic microcircuitry, it represents a formidable challenge. This analysis must necessarily be coordinated between the radiation effects experts and the design engineers, and its success will rely on knowledge of the susceptibilities of the candidate components to the various SEE mechanisms.
This knowledge may be based on a number of factors including laboratory radiation test data, component manufacturer's analysis, heritage of the circuit design cell library and process methods, and previous flight data. Where insufficient data exists, it is the role of the radiation test engineers providing support to the flight project to conduct accelerator radiation tests for assessing proton and heavy ion induced SEE vulnerabilities. Ultimately, the vulnerabilities of each candidate part must be identified and the associated rates for each possible single event effect must be calculated for the radiation environment established in the requirements. The contributions to the allocated subsystem error budget must then be assessed, and as indicated in figure 2.6 and in Section 6, hardening or mitigation approaches identified where necessary.
The SEECA approach would now be applied to the subsystem level with the possible failure modes gauged according to what the effect might be and whether or not it reaches the boundary of the subsystem to impact the allocated error budget. In this sense, the use of SEU soft parts might be allowed even within a subsystem designated error-critical, provided error mitigation techniques within the subsystem prevented the errors from reaching the subsystem boundaries. Through this process, the error budget is managed through the completion of detailed design, and with control of cost and complexity as the driving forces.
The ultimate endpoint test of the design will be actual flight performance, since it is not possible to fully simulate the space environment at the system level. Even so, the radiation effects engineers can play a crucial role in design verification. This takes place on two counts, the verification of SEE sensitivity in actual flight lot parts to confirm assumptions made during earlier design stages and also subsystem level flight prototype tests at particle accelerators to verify subsystem performance with errors induced in specific locations within the subsystem. This latter type of test, if properly planned and executed, can validate error mitigation techniques as well as hardware performance.
This type of in situ testing can be important for two reasons. First it can serve to validate error mitigation approaches in the subsystem design by demonstrating that errors at the component level are not sensed at the subsystem output, or that when errors disrupt the performance, the recovery is accomplished within requirements. Also, even though component tests are usually done with test fidelity to the application as an objective, in situ testing can help in discovering the circuit performance under actual operating conditions which may differ from component level test conditions. As an example, component tests might be conducted at clock frequencies which differ from the application. SEE sensitivity can be highly dependent on clock rates.
The process of SEECA must be part of an integrated effort beginning in mission planning phases. Identification of functional requirements, along with the criticality of those functions provide the basis for the analysis. Unambiguous statement of these requirements, along with comprehensive statement of the SEE relevant aspects of the environment must then be included in the procurement specifications. From this foundation, the hardware level requirements for various subsystems follow, and finally these requirements flow down to the component level.
In this latter stage, the concepts behind the system functional criticality evaluation can be reapplied at the subsystem level with the understanding that possible SEE failure mechanisms must be identified at the component level, and the effects of those SEEs tracked to the board or subsystem boundaries to assess their effects on the system function. The team comprised of the radiation effects experts and the subsystem engineers then evaluate the need for SEE hardening and mitigation techniques based on the expected frequency of occurrence in the given orbit, the severity of the occurrence, the error budget allocated to that particular subsystem, and the cost and complexity of reducing the occurrence or impact of SEE in one part of the subsystem versus another.
Elements of SEECA are found throughout the process, from mission planning, to requirements definition and environment specification, to system and subsystem criticality assignments, to detailed subsystem design, and finally test and verification. In each of these stages, radiation environmental and test scientists should provide input and work as integrated members of the design or procurement effort. These individuals will likely belong to both the procurement and the contracting activities, and their roles should be identified clearly in the beginning stages of the procurement.
The benefits of a disciplined approach to single event effect management result in the deployment of a reliable system with known risk levels, the aversion of costly retrofits of SEE hardened parts or mitigation schemes, and the minimization of overall system complexity and costs.
![]()
Introduction
1. The SEE Problem
2. Functional Analysis and Criticality
3. Ionizing Radiation Environment Concerns
4. Effects in Electronic Devices and SEE Rates
5. SEU Propagation Analysis: System Level Effects
6. SEE Mitigation: Methods of Reducing SEE Impacts
7. Managing SEEs: System Level Planning
8. SEE Criticality Assessment Case Studies
{kind=link}
{kind=link}